恶意代码分类数据篇
2016-11-22
VX Heaven
VX Heaven在很多恶意代码分类的文章中都有提到,应该算是一个不错的数据集,一开始进入这个网站并没有找到想要的数据集。通过这两天的分析查找,发现了两个有意思的链接,一个是source code of computer viruses,一个是computer virus collection,通过名字就可以知道这两个链接的意思。链接如下:
- source: http://vxheaven.org/src.php?show=all
- collection: http://vxheaven.org/vl.php
Virus Source
该链接提供的virus总共有375个,基本都是virus的汇编文件,可以直接提取opcode.文件数量虽然不是很多,但是一个一个点击下载还是比较麻烦,而且链接点击进去之后是关于恶意程序的具体介绍,也无法使用迅雷下载页面全部链接,考虑使用爬虫获取页面所有链接,并进一步下载所有文件和恶意程序的具体描述信息。下面对关键步骤进行记录一下,完整代码可以参考Github上的vxheaven.py.
使用正则匹配,解析virus source文件列表
def GetMalcode(url):
soup = GetPage(url)
results = soup.findAll('a', {'href': re.compile(r'/src.php\?info=(.+)')})
for result in results:
tmp = result.get('href')
src_url = ''.join(['http://vxheaven.org', tmp])
GetMalInfo(src_url)
解析virus具体信息,包括title, description, author, upload time, file name.因为并不是所有页面都包含这些信息,所以要对作简单的判断,不然程序会抛出异常
tmp = result.find('h2')
if tmp:
malTitle = tmp.renderContents()
malDesc = ''
malAuthor = ''
malDate = ''
tmp = result.findAll('p')
lenth = len(tmp)
if (lenth > 0):
malDesc = tmp[0].renderContents()
if (lenth > 1):
malAuthor = tmp[1].renderContents()
if (lenth > 2):
malDate = tmp[2].renderContents()
解析virus下载地址.页面中下载文件是通过post提交form来获取文件下载链接,通过模拟操作发现会有一步人机验证,导致响应403 forbidden的问题.通过分析下载链接,发现可以通过base64解码提交参数,拼凑出文件下载链接.
tmp = result.find('input', {'type': 'hidden'}, {
'name': 'file'}).get('value')
tmp = tmp.replace('@', '=')
malFile = base64.b64decode(tmp)
malSrc = ''.join(['http://vxheaven.org/dl/', malFile])
Virus collection
该链接提供了virus的可执行程序集合,页面列表根据Kaspersky的检测结果进行命名.点击进入链接一直到下载文件页面会得到提示
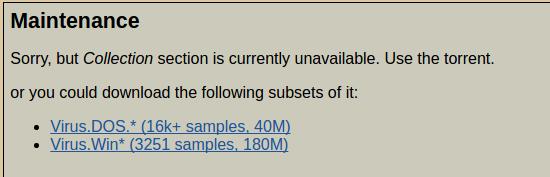
根据提示可以下载到两个virus collection的subset,其中
- Virus.Dos文件中包含
16862个文件 - Virus.Win文件中包含
3251个文件
虽然提示可以通过torrent下载全部collection,但是页面中并没有给出具体的下载拦截.通过查找vx heaven的FAQ页面以及forum,找到http://vxheaven.org/forum/viewtopic.php?id=141,可以通过该页面提供的地址下载viruses-2010-05-18.tar.bz2.torrent.总共含有270K samples, 45Gb, 62Gb unpacked, virus list
另外,推荐一个下载学术资源的网站Academic Torrents,提供了很多数据,最初我下载的virus collection(VX Heaven Virus Collection 2010-05-18)也是在上面找到的.
备注: 在接下来的恶意代码检测,以及恶意代码反汇编提取操作码(OpCode)的实验中,皆使用virus collection subset数据集。
ZeuS Tracker
这也是一个提供了恶意代码资源的网站,除了有恶意代码资源,同时还有一些IP的blocklist,都可以用作参考。因为要做恶意代码分类的研究,所以重点关注恶意代码资源的下载.
该网站资源链接比较容易找到,如下
该页面提供了66个恶意代码资源,包含virus的url, hash, size 和 virus total的检测结果等信息.
虽然数据量不大,但是手动下载也是挺麻烦,所以还是通过python脚本来实现下载。关键解析代码如下,完整资源参考Github上的zeustracker.py
results = soup.findAll('a', {'title': 'download file'}, {'href': re.compile(r'monitor.php?show=(.+)')})
for result in results:
tmp = result.get('href')
index_show = tmp.index('show=')
index_hash = tmp.index('&hash=')
index_down = tmp.index('&download')
file_suffix = tmp[index_show + 5: index_hash]
file_name = tmp[index_hash + 6: index_down]
file = '.'.join([file_name, file_suffix])
src_url = ''.join(['https://zeustracker.abuse.ch/', tmp])
GetFile(src_url, file)
Virus Detection
在得到数据之后,首先需要对数据进行检测,确定数据是否是恶意样本。对恶意样本检测可以通过杀软进行检测,如Kaspersky,或者在线进行检测,通过检测结果可以确定数据是否是恶意样本,同时也能够得到恶意样本的类型,为接下来的研究做好基础准备。
以下是常用的恶意代码在线检测网站
提供Public Api可以对文件进行检测
File Purging
对下载的数据集进行检测之后,得到进行分析使用的恶意样本。在对恶意样本进行反汇编之前,还需要完成几个步骤:文件类型识别,加壳文件脱壳。其中文件类型识别主要是从数据样本中提取出可执行文件,因为本次分析主要是针对可执行文件进行分析,对于恶意脚本如JavaScript的分析和本次分析方法不同,放在数据集中对结果产生影响;对加壳文件脱壳,主要是为了得到准确的反汇编代码,因为很多恶意软件通过加壳混淆了原有代码,直接进行反汇编得不到准确反汇编代码,影响分析。
文件类型
在Windows系统中,通常根据文件后缀名来判断文件类型,暂不考虑在类Unix系统中没有后缀名这种概念,单纯在Windows系统中,根据文件后缀来判断文件类型也存在很大问题,是一种很不准确的方法。通常来说,识别文件类型一般是通过识别文件头信息,也叫做魔数(magic number),比如常见的exe文件头为4D 5A 50。在类Unix系统中,通常使用file命令来查看文件类型,而file命令的本质也是根据magic number进行判断。
本实验中,通过分析file命令的源码,定位出识别文件类型的核心代码python-magic,安装之后就可以引入magic模块对文件类型进行识别
def filetype(filename):
ms = magic.open(magic.NONE)
ms.load()
file_type = ms.file(filename)
ms.close()
return file_type
文件脱壳
得到实验所需要的可执行文件之后,需要检测文件是否加壳,并对加壳文件进行脱壳。程序加壳检测一般使用PEiD,使用最新版可以检测出大多数加壳类型和具体版本信息,根据检测到的壳使用相应的脱壳工具,一般常用的有upxunpacker, pecompact2.
在实际实验过程中,发现使用python-magic对文件进行类型检测的同时,也能够识别出大多数加壳文件的加壳类型,结合PEiD工具可以更好地对文件进行脱壳
Virus Disassembly
因为要提取恶意样本的操作码(OpCode),那么就需要恶意样本是二进制可执行文件。通过对数据集文件类型进行分析,发现数据集中不仅包含可执行文件(加壳,不加壳),同时也含有大量文本文件,如HTML、XML等,对于该部分文件,没有操作码(OpCode)的概念,所以在本研究中暂时不作考虑。也正是基于此原因,需要首先对数据的文件类型进行分析。
反汇编工具
在进行反汇编恶意样本之前,需要首先选定进行反汇编的工具,因为不同的反汇编工具采用不同的反汇编算法,不同的反汇编算法得到的结果也不尽相同。
常用的反汇编算法可以分为以下几种:
- 梯度下降法
梯度下降法钱强调控制流的概念,根据一条指令是否被另一条指令引用来决定是否对其进行反汇编
代表工具
IDA Pro
- 线性扫描反汇编
线性扫描反汇编算法采用一种非常简单的方法来确定需要反汇编的指令位置:指令开始和结束的位置。从代码段的第一个字节开始,以线性模式扫描整个代码段,逐条反汇编每条指令,直到完成整个代码段
代表工具
Windbg、Ndisasm
通过对几个恶意样本的以及上一步对恶意样本的分类结果进行分析,可以发现数据集中恶意样本种类繁多,而且16位、32位恶意程序都有,如果使用ndisasm进行反汇编,需要人工分析不同种类样本的入口地址,以确定代码段起始位置,否则反汇编得到的结果不准确,而且ndisasm工具不提供自动分析功能,想比较而言,IDA Pro虽然比较繁琐,分析比较慢,但是结果比较准确,而且可以自动选择合适的处理器型号、文件类型等参数,对恶意样本进行自动分析,并将结果保存到idb数据库,可以使用IDA Pro直接打开继续上一次分析。
选定反汇编工具IDA Pro之后,接下来对恶意样本进行反汇编处理。
批量反汇编
虽然IDA Pro是一款非常好用的静态反汇编工具,但是并不能一次性打开多个文件进行自动分析,所以考虑使用脚本调用IDA Pro的接口进行分析,并将分析结果,及反汇编代码进行保存。IDAPython是IDA Pro的一种扩展脚本,可以实现很多IDA Pro本身不具有的功能。在这种思路下, 很自然想到使用IDAPython编写脚本来对恶意样本逐一进行分析,并保存结果。
原本是按照编写IDAPython脚本的思路对恶意样本进行分析,偶然发现看雪论坛上一篇文章IDA批量模式,发现IDA Pro还可以命令行模式运行(idal -A -Sscript.idc input_file),而且功能和GUI界面相同,也能够根据参数对文件分析,此外还可以加载后期处理脚本,这无疑是一种处理恶意样本更好的方法。
Windows平台使用idaw启动Mac系统使用idal命令启动
这里要说明一下,查阅相关资料都是
idag命令,但是我使用的版本中没有idag,只有idal,这应该是不同版本的问题,使用过程中和相关资料中idag功能相同,所以没有深究原因,感兴趣的可以分析一下
下面对分析过程中使用到的参数进行简单说明:
-A让ida自动运行,不需要人工干预。也就是在处理的过程中不会弹出交互窗口,但是如果从来没有使用过ida那么许可协议的窗口无论你是否使用这个参数都将会显示。-c参数会删除所有与参数中指定的文件相关的数据库,并且生成一个新的数据库。-S参数用于指定ida在分析完数据之后执行的idc脚本,该选项和参数之间没有空格,并且搜索目录为ida目录下的idc文件夹。-B参数指定批量模式,等效于-A –c –Sanylysis.idc.在分析完成后会自动生成相关的数据库和asm代码。并且在最后关闭ida,以保存新的数据库。-h显示ida的帮助文档
默认情况下,IDA分析完文件之后,会自动在文件目录下生成一个idb数据库文件,数据库文件以输入进行分析文件去掉后缀之后的文件名进行命名。但是因为本次实验中使用的数据集很多文件只是后缀有区别,前面文件名相同,所以要以完整文件名保存相应的分析结果。这种情况下,自定义idc脚本来完成分析后期工作比较方便。
下面是使用到的analysis_fullname.idc脚本,保存在ida目录下的idc文件夹:
#include <idc.idc>
static main()
{
// turn on coagulation of data in the final pass of analysis
SetShortPrm(INF_AF2, GetShortPrm(INF_AF2) | AF2_DODATA);
Message("Waiting for the end of the auto analysis...\n");
Wait();
Message("\n\n------ Creating the output file.... --------\n");
auto file = GetInputFilePath();
auto asmfile = file + ".asm";
auto idbfile = file + ".idb";
WriteTxt(asmfile, 0, BADADDR); // create the assembler file
SaveBase(idbfile, 0); // save the idb database
Message("All done, exiting...\n");
Exit(0); // exit to OS, error code 0 - success
}
接下来就可以通过python脚本遍历数据集的恶意样本,调用idal来对样本进行分析,并保存反汇编结果了。完整代码可以参考wingenasm.py,核心代码如下:
idalPath = "//usr//local//src//ida-pro-6.4//idal"
idcPath = "//usr//local//src//ida-pro-6.4//idc//analysis_fullname.idc"
def traveseFile(path):
for parent, dirnames, filenames in os.walk(path):
for filename in filenames:
filepath = os.path.join(parent, filename)
filepath = filepath.replace(' ', '\ ').replace('(', '\(').replace(')', '\)')
genAsm(filepath)
def genAsm(filepath):
ExecStr = idalPath + " -c -A -S" + idcPath + " " + filepath
os.system(ExecStr)
OpCode/ByteCode generation
在对文件进行反汇编之后,提取文件的OpCode.文章中对文件使用两种表示方法,一种是OpCode,通过反汇编代码提取,这种表示方法适用于IDA Pro能够识别出文件类型的文件;另一种采用ByteCode,提取二进制代码的序列,这种方法适用于IDA-Pro无法识别出文件类型,即作为Binary File进行处理的文件。
通过大量分析IDA-Pro反汇编结果,发现导出的反汇编文件都会含有一个ida pro解析的头文件,在这段信息中,大多数会含有文件格式信息,以及进行反汇编的处理器型号等。如果是无法识别格式的文件,会作为Binary File进行处理,可以通过检测该部分信息识别文件格式是否能够被ida pro识别。文件头信息基本如下
;
; +-------------------------------------------------------------------------+
; | This file has been generated by The Interactive Disassembler (IDA) |
; | Copyright (c) 2013 Hex-Rays, <support@hex-rays.com> |
; | License info: 48-B611-7394-02 |
; | Zhiyong Man, Baidu |
; +-------------------------------------------------------------------------+
;
; Input MD5 : A1D351FFA49103264F0C042103C08358
; Input CRC32 : 3AFE2DD3
; File Name : /virus.win/normal/COM executable for MS-DOS/Virus.Win16.Lucky.423
; Format : Binary file
; Base Address: 0000h Range: 0000h - 01A7h Loaded length: 01A7h
;
文件识别处理代码片段如下
def isOpCodeFile(lines):
for line in lines:
if ('; Format : Binary file' in line):
return False
return True
def traveseFile(path):
...
if(isOpCodeFile(lines)):
getOpCode(lines, filename)
else:
getByteCode(parent, filename)
OpCode
IDA-Pro反汇编出来的文件会含有一个额外信息,如寄存器名称,寄存器地址等,此外还有一些函数名信息。
在这些额外信息中,一些信息,如寄存器名称,文件格式等会通过类似注释的方式,以;作为开头输出,如
; Segment type: Regular
还有一些额外信息,如函数名,也会作为行首输出,如
sub_10 proc near ; CODE XREF: sub_1799+69p
具体的反汇编代码,会以两个tab作为开头输出,如
push dx
push ax
call CREATESOLIDBRUSH
mov word_3088, ax
push 0Fh
call GETSYSCOLOR
push dx
push ax
根据这些特征,可以通过脚本提取出OpCode
if(len(prefix) > 2 and prefix[0:2] == '\t\t'):
prefix = prefix.strip()
if(prefix == '' or prefix is None):
continue
if(prefix[0] == '.' or prefix[0] == ';'):
continue
opcode = ''.join([prefix.split('\t')[0], '\n'])
ByteCode
对于IDA-Pro无法识别的Binary File,需要对文件进行重新处理,以二进制读取文件,并将读取的字符转成16进制的hex形式
with open(rawpath, 'rb') as rawfile:
rawfile.seek(0, 0)
while True:
byte = rawfile.read(1)
if byte == '':
break
else:
hexstr = "%s" % byte.encode('hex')
提取代码可以参考getOpCode.py
Summary
至此,数据预处理的过程就完成了,接下来开始进行对OpCode/ByteCode的n-gram提取。
这一部分工作,应该是工作量最大的一部分工作,ML本身就是数据驱动,数据如果处理得好,后期训练出来的分类器效果就会好。这一部分工作算是反复做了三遍,不断发现新的问题,不断解决问题,最终勉强算是完成了这部分工作吧。希望接下来的工作能够更加顺利。
References
[1] IDA批量模式